商机详情 -
自动巡检智慧运维平台供应商
智慧运维平台的引入不*是技术变革,更是深刻的组织与文化变革。它要求运维团队从传统的“脚本英雄”和“救火队员”,转型为具备数据科学思维、擅长使用智能化工具的“运维分析师”或“平台工程师”。企业需要为此制定系统的培训计划,鼓励团队成员学习数据分析、Python编程、机器学习基础等新技能。同时,运维与开发、业务团队的边界将进一步模糊,需要建立更强的协作机制(如SRE模式)。管理层的支持和清晰的角色定义,是平稳度过这一变革期、充分释放平台价值的重要保障。形成可视化报表和动态图表。自动巡检智慧运维平台供应商

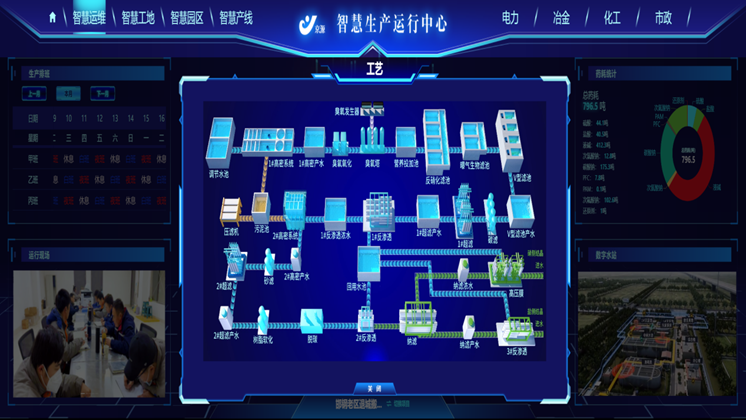
在网络领域,智慧运维平台实现了网络性能管理与诊断(NPMD)的深化。它通过NetFlow/sFlow/IPFIX等流数据,结合主动拨测和SNMP信息,构建出端到端的网络可视化地图。AI算法能够实时分析网络流量模式,检测DDoS攻击、网络滥用或异常数据传输行为。当应用出现问题时,平台能够快速进行网络路径分析, pinpoint是数据中心内部、跨云链路还是运营商网络出现了延迟或丢包,从而将网络团队从繁琐的命令行排查中解放出来,实现准确、高效的网络故障定界与诊断。自动巡检智慧运维平台供应商优化调度提高运营效率和服务质量。
作为一个复杂系统,智慧运维平台自身也必须具备高度的可观测性。平台需要监控其数据采集管道的健康度、数据处理的延迟、AI模型的准确率、API的调用性能等。当平台自身出现数据断流、分析延迟或错误时,应能自我感知、自我告警。确保平台自身的稳定、可靠是其为业务系统提供可信服务的前提,这也是“Eating your own dog food”理念在运维领域的体现。在DevOps文化中,智慧运维平台扮演着“反馈中枢”的角色。它将生产环境的真实运行数据(如性能指标、错误日志、用户反馈)持续、透明地反馈给开发团队。这些数据被集成在CI/CD流水线中,成为定义“Done”的标准之一(不*功能完成,还需满足性能基线)。这种基于数据的快速反馈闭环,驱动开发人员编写更健壮、更易于监控的代码,促进了开发与运维的深度协作,是构建高质量、高韧性软件系统的关键。
企业引入智慧运维平台不应一蹴而就,应遵循循序渐进的成熟度模型。通常可分为四个阶段:第一阶段是“统一监控”,整合工具与数据,实现可观测性;第二阶段是“场景智能化”,在告警压缩、异常检测、根因分析等关键场景引入AI,提升效率;第三阶段是“流程自动化”,将诊断和修复动作自动化,实现部分场景的自愈;第四阶段是“业务运营”,将运维洞察与业务运营深度融合,驱动业务决策与创新。企业需评估自身现状,选择合理的起点和演进路径,确保每一步投资都能带来实实在在的收益。地图支持按特定需求检索项目。
智慧运维平台是企业数字化转型旅程中的“稳定器”与“加速器”。一方面,数字化转型催生了微服务、容器化、混合云等复杂技术架构,这些架构的运维难度呈指数级增长,传统手段已难以为继,智慧运维成为保障其稳定运行的必然选择。另一方面,智慧运维平台所产生的数据洞察,能够反向赋能业务创新。例如,通过分析用户行为流量模式,可以为准确营销和产品迭代提供建议;通过洞察供应链系统性能,可以优化物流效率。因此,智慧运维不*是支撑数字化转型的底层能力,其本身也是通过技术手段重塑业务流程、创造新价值的关键组成部分。及时接收预警信息处理突发情况。自动巡检智慧运维平台供应商
绩效对比分析为项目考核提供依据。自动巡检智慧运维平台供应商
混沌工程是通过在生产环境中故意引入故障,以验证系统韧性的一种实践。智慧运维平台与混沌工程平台联动,构成了“攻防”结合的完美体系。混沌工程平台负责“攻击”(如随机终止Pod、模拟网络延迟),而智慧运维平台则负责“防守”监控,实时观测系统在扰动下的表现,记录各项指标的异常波动,并验证现有的告警、自愈和容灾机制是否如期生效。通过这种主动的“故障演练”,能够持续发现系统中的脆弱点,并驱动其加固,从而系统性提升企业的业务连续性能力。自动巡检智慧运维平台供应商