商机详情 -
北京大屏模块智慧运维平台
企业引入智慧运维平台不应一蹴而就,应遵循循序渐进的成熟度模型。通常可分为四个阶段:第一阶段是“统一监控”,整合工具与数据,实现可观测性;第二阶段是“场景智能化”,在告警压缩、异常检测、根因分析等关键场景引入AI,提升效率;第三阶段是“流程自动化”,将诊断和修复动作自动化,实现部分场景的自愈;第四阶段是“业务运营”,将运维洞察与业务运营深度融合,驱动业务决策与创新。企业需评估自身现状,选择合理的起点和演进路径,确保每一步投资都能带来实实在在的收益。移动端支持故障报告快速上传。北京大屏模块智慧运维平台

业务连续性规划(BCP)严重依赖于对系统依赖关系和风险点的准确认知。智慧运维平台中动态生成的应用拓扑图、梳理出的关键业务链路、以及历史故障影响范围分析,为制定准确的BCP提供了较真实的数据基础。平台可以模拟不同灾难场景(如单个AZ故障、数据库宕机)对业务的影响,并验证容灾切换方案的有效性。这使得BCP从一份静态的文档,变成了一个基于实时系统状态、可数据化验证的动态管理过程。没有一个平台能解决所有问题,因此智慧运维平台的生态与集成能力至关重要。良好的平台应提供丰富的API、SDK和插件机制,能够轻松与现有的ITSM、CMDB、自动化工具、通信平台(如Slack、钉钉)以及云服务商的原生监控服务集成。通过构建一个开放的生态系统,智慧运维平台可以成为运维工具链的“指挥中心”,聚合各方数据与能力,而不必替代所有工具,从而以更灵活、更低成本的方式创造价值。北京大屏模块智慧运维平台Web 端监控水源地等设施运行数据。
数字孪生技术为智慧运维提供了前所未有的“沙盘推演”能力。它通过创建一个与物理系统完全同步的虚拟镜像,使得运维人员可以在不影响真实业务的前提下,在数字世界中进行各种“假设分析”(What-if Analysis)。例如,可以模拟一次大规模促销活动的流量冲击,观察系统瓶颈会出现在何处;可以模拟某个核心交换机故障,验证现有的高可用方案是否有效;甚至可以模拟新版本发布,预测其对系统稳定性的影响。这种能力将运维从“事后补救”提升到了“事前规划”的战略高度,极大地增强了系统的韧性与可控性。
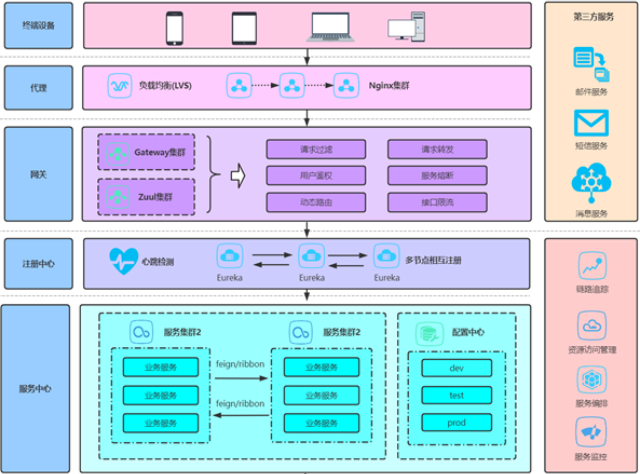
智慧运维平台以 “云原生 + 人工智能” 为主要技术架构,构建了分层解耦的分布式体系。底层基于容器化技术实现资源弹性伸缩,支持千万级设备接入与百万级并发请求处理;中间层通过微服务架构拆分监控、告警、调度等主要模块,确保各功能单独迭代且协同高效;顶层则集成机器学习引擎与知识图谱系统,为智能化决策提供算法支撑。这种架构设计打破了传统运维的硬件依赖,实现了从 “物理部署” 到 “云边协同” 的跨越,可适配不同规模企业的 IT 基础设施,为后续智能化运维能力的落地奠定了坚实基础。优化资源分配提高工作效率。
智慧运维平台的成功,高度依赖于输入数据的质量。低质量的数据将导致“垃圾进,垃圾出”的尴尬局面。因此,在平台建设初期就必须建立完善的运维数据治理体系。这包括:制定统一的数据采集标准与规范;建立数据血缘关系,确保数据的可信溯源;对数据进行分类、打标,明确其敏感度和生命周期;清洗和预处理噪声数据、缺失数据。良好的数据治理确保了平台分析结果的准确性和好的性,是构建可靠AI模型的基础,也是平台能否被业务团队信任和采纳的关键。触控语音手势交互简化操作流程。北京大屏模块智慧运维平台
三大模块协同实现管理闭环。北京大屏模块智慧运维平台
智慧运维平台对传统IT基础设施监控进行了整体智能化升级。它不仅能通过Agent和SNMP等手段采集CPU、内存、磁盘等基础指标,更能利用AI算法为每台服务器、网络设备建立个性化的性能基线。当资源使用率出现违背基线的异常波动时,即使未超过固定阈值,平台也能敏锐捕捉并告警。同时,平台能够关联分析基础设施层与上层应用层的性能数据,快速判断一个应用卡顿是否由底层虚拟机资源争抢引起,实现了从孤立的设备监控到服务于业务体验的全局监控视角转变。北京大屏模块智慧运维平台