商机详情 -
京源智慧运维平台供应
可观测性(Observability)是智慧运维的基石,它超越了传统的监控概念,强调从系统外部输出(如日志、指标、追踪)中,能够理解和推断系统内部状态的能力。一个具备高度可观测性的平台,能够让我们不仅知道系统“出了什么问题”,更能理解“为什么会出问题”。它通过整合日志(Logging)记录离散事件、指标(Metrics)反映聚合状态、链路追踪(Tracing)描绘请求全景,构建了理解复杂分布式系统的三维数据模型。没有完善的可观测性数据基础,后续的AI分析与自动化就如同无源之水,智慧运维也就无从谈起。三大模块协同实现管理闭环。京源智慧运维平台供应

传统运维模式高度依赖人工经验与阈值告警,通常在故障发生并对业务造成影响后,团队才被动介入,整个过程耗时耗力且用户体验受损。智慧运维平台通过引入AI算法,实现了从“被动响应”到“主动预见”的根本性变革。平台能够对海量历史与实时数据进行分析,准确识别出系统性能的衰减趋势、潜在瓶颈以及异常模式,并在故障发生前发出预警,指导运维团队提前进行资源调配或修复,从而将故障扼杀在萌芽状态。这种范式转变不仅大幅提升了系统的稳定性和可用性,更将运维团队从繁琐的告警噪音中解放出来,专注于更高价值的战略优化工作。京源智慧运维平台供应实时采集各类水务设备运行数据。

智慧运维平台的出现,标志着IT运维管理经历了一场深刻的范式变革。传统的运维模式高度依赖人工,运维人员如同“救火队员”,被动地响应各类告警和故障。他们需要登录不同的系统查看日志、监控性能指标,凭借个人经验进行问题定位和根因分析。这种方式不仅效率低下,而且在面对日益复杂的混合IT架构(包括物理机、虚拟机、容器、多云环境)时,往往力不从心,难以预见潜在风险。智慧运维平台的主要突破在于,它通过构建一个统一、集中的数据底座,汇聚了从基础设施、网络、应用到业务层的全栈遥测数据。这改变了以往数据孤岛的局面,为后续的智能分析奠定了坚实基础。它不再是简单的监控工具,而是一个集成了数据采集、处理、分析和可视化的综合性中枢,将运维工作从被动、手工、孤立的模式,展示至主动、自动化、协同的新纪元,这是运维领域从“技艺”走向“科学”的关键一步。
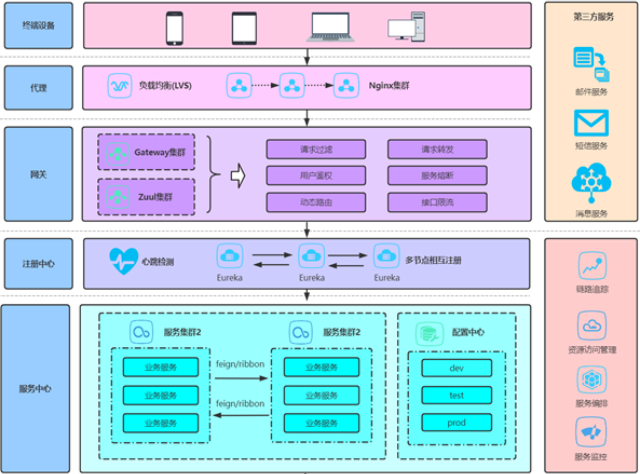
智慧运维平台以 “云原生 + 人工智能” 为主要技术架构,构建了分层解耦的分布式体系。底层基于容器化技术实现资源弹性伸缩,支持千万级设备接入与百万级并发请求处理;中间层通过微服务架构拆分监控、告警、调度等主要模块,确保各功能单独迭代且协同高效;顶层则集成机器学习引擎与知识图谱系统,为智能化决策提供算法支撑。这种架构设计打破了传统运维的硬件依赖,实现了从 “物理部署” 到 “云边协同” 的跨越,可适配不同规模企业的 IT 基础设施,为后续智能化运维能力的落地奠定了坚实基础。移动端让管理者随时随地监管系统。
智慧运维平台使得运维管理可以从粗放式的“设备可用”升级为精细化的“服务等级目标(SLO)”管理。平台能够基于用户体验数据,自动计算关键业务服务的SLO(如“99.9%的请求响应时间小于200ms”),并实时监控其达成情况。通过“错误预算”的概念,将SLO的消耗情况可视化,为团队的发布节奏和风险决策提供客观依据。当错误预算即将耗尽时,平台会发出预警,促使团队将重心从新功能开发转移到稳定性建设上,实现了业务风险与创新速度的科学平衡。项目状态看板动态呈现全流程转化情况。京源智慧运维平台供应
资源匹配模拟优化项目开工时间规划。京源智慧运维平台供应
在现代应用性能管理(APM)中,智慧运维平台通过嵌入应用的探针,采集从用户端到服务端全链路的深度数据。它不仅能展示应用的响应时间、错误率,更能通过代码级追踪,将性能瓶颈定位到具体的数据库查询、第三方API调用或某行低效代码。平台利用机器学习对应用依赖关系进行动态发现和建模,当某个微服务性能下降时,能清晰展示出其“下游”影响的所有服务。这种深度洞察使得开发与运维团队拥有了共同的语言,能够快速协作,持续优化用户体验。京源智慧运维平台供应